








Nội Dung Chính
Đã bao giờ bạn hình dung làm sao một robot của công cụ tìm kiếm có thể phân tích dữ liệu của một website để index không? Đôi lúc bạn muốn googlebot nhanh index trang web của mình hoặc không index một trang cụ thể nào đó.
Vậy làm cách nào bây giờ? Tôi có thể trả lời ngay cho bạn – tạo file robots.txt cho wordpress ngay.
Bài viết này sẽ hướng dẫn cho bạn:
- Hiểu rõ khái niệm robots.txt là gì
- Cấu trúc cơ bản của một file robots.txt
- Có những lưu ý gì khi tạo lập robots.txt
- Tại sao phải cần robots.txt cho một website
- Cách tạo lập 1 file hoàn chỉnh
Robots.txt là gì?

File robots.txt chuẩn là một tập tin văn bản đơn giản có dạng .txt. Tệp này có chức năng hướng dẫn robot web (hoặc robot của các công cụ tìm kiếm) cách thu thập dữ liệu trên các trang web.
File robots.txt là một phần của Robots Exclusion Protocol (REP). Đây là một nhóm các tiêu chuẩn web quy định cách robot thu thập dữ liệu trên web, truy cập, index nội dung và cung cấp nội dung đó cho người dùng.
REP cũng bao gồm các lệnh như meta robots, page-subdirectory, site-wide instructions. Nó hướng dẫn các công cụ tìm kiếm xử lí các liên kết. (ví dụ: follow hay nofollow link)
Trên thực tế, tạo file robots.txt cho wordpress giúp các nhà quản trị web link hoạt, chủ động hơn trong việc cho phép hay không cho các con bot của công cụ tìm kiếm index một số phần nào đó trong trang web của mình.
Cú pháp của tệp robots.txt
Các cú pháp được xem là ngôn ngữ riêng của các tập tin robots.txt.
Có 5 thuật ngữ phổ biến mà bạn có thể bắt gặp trong một file robots.txt. Chúng bao gồm:
- User-agent: Phần này là tên của các trình thu thập dữ liệu web. (ví dụ: Googlebot, Bingbot,…)
- Disallow: Lệnh này được sử dụng để thông báo cho các user-agent không thu thập bất kì dữ liệu URL cụ thể nào. Mỗi URL chỉ được sử dụng 1 dòng disallow.
- Allow (chỉ áp dụng cho Googlebot): Lệnh này thông báo cho Googlebot rằng nó có thể truy cập một trang hoặc thư mục con. Mặc dù các trang hoặc các thư mục con của nó có thể không được phép.
- Crawl-delay: Phần này thông báo cho các web crawler biết rằng nó phải đợi bao nhiêu giây trước khi tải và thu thập nội dung của trang. Tuy nhiên, lưu ý rằng Googlebot không thừa nhận lệnh này. Bạn có thể cài đặt tốc độ thu thập dữ liệu trong Google Search Console.
- Sitemap: Lệnh này được sử dụng để cung cấp các vị trí của bất kì XML sitemap nào được liên kết với URL này. Lưu ý lệnh này chỉ được hỗ trợ bởi Google, Ask, Bing và Yahoo.
Pattern-matching
Trên thực tế các file robot.txt wordpress khá phức tạp để có thể chặn hoặc cho phép các con bots vì chúng cho phép sử dụng tính năng Pattern-matching để bao quát một loạt các tùy chọn của URL.
Google và Bing cho phép sử dụng 2 biểu thức chính để xác định các trang hoặc thư mục con mà SEO muốn loại trừ. Hai kí tự này là dấu hoa thị (*) và ký hiệu đô la ($).
- * là kí tự đại diện cho bất kì chuỗi kí tự nào – có nghĩa là nó được áp dụng cho mọi loại bots của các công cụ tìm kiếm.
- $ là kí tự khớp với phần cuối của URL.
Định dạng cơ bản của file robots.txt

Tuy nhiên, bạn vẫn có thể lược bỏ các phần “crawl-delays” và “sitemap”.
Đây là định dạng cơ bản để tạo file robots.txt cho WordPress hoàn chỉnh. Tuy nhiên trên thực tế thì tệp robots.txt có thể chứa nhiều dòng User-agent và nhiều chỉ thị của người dùng.
Chẳng hạn như các dòng lệnh: disallows, allows, crawl-delays, …
Trong file robots.txt chuẩn, bạn có thể chỉ định cho nhiều con bot khác nhau. Mỗi lệnh thường được viết riêng biệt cách nhau bởi 1 dòng.
Trong một file robots.txt wordpress bạn có thể chỉ định nhiều lệnh cho các con bot bằng cách viết liên tục không cách dòng.
Tuy nhiên trong trường hợp một file robots.txt có nhiều lệnh đối với 1 loại bot thì mặc định bot sẽ làm theo lệnh được viết rõ và đầy đủ nhất.
Lưu ý về file robots.txt chuẩn
- Để chặn tất cả các website crawler không được thu thập bất kì dữ liệu nào trên website bao gồm cả trang chủ. Chúng ta hãy sử dụng cú pháp sau:
User-agent: *
Disallow: /
- Để cho phép tất cả các trình thu thập thông tin truy cập vào tất cả nội dung trên website bao gồm cả trang chủ. Chúng ta hãy sử dụng cú pháp sau:
User-agent: *
Disallow:
- Để chặn trình thu thập thông tin của Google (User-agent: Googlebot) không thu thập bất kì trang nào có chứa chuỗi URL www.example.com/example-subfolder/. Chúng ta hãy sử dụng cú pháp sau:
User-agent: Googlebot
Disallow: /example-subfolder/
- Để chặn trình thu thập thông tin của Bing (User-agent: Bing) tránh thu thập thông tin trên trang cụ thể tại www.example.com/example-subfolder/blocked-page. Chúng ta hãy sử dụng cú pháp sau:
User-agent: Bingbot
Disallow: /example-subfolder/blocked-page.html
Ví dụ cho file robots.txt chuẩn
Dưới đây là ví dụ về tệp robots.txt hoạt động cho trang web www.example.com:
- User-agent: *
- Disallow: /wp-admin/
- Allow: /
- Sitemap: https://www.example.com/sitemap_index.xml
Theo bạn, cấu trúc file robots.txt này có ý nghĩa gì? Để Beeseo giải thích.
Điều này chứng tỏ bạn cho phép toàn bộ các công cụ tìm kiếm theo link
Điều này chứng tỏ bạn cho phép toàn bộ các công cụ tìm kiếm theo link www.example.com/sitemap_index.xml để tìm đến file robots.txt phân tích và index toàn bộ các dữ liệu trong các trang trên website của bạn ngoại trừ trang www.example.com/wp-admin/
Robots.txt file hoạt động như thế nào?
Các công cụ tìm kiếm có 2 nhiệm vụ chính:
- Crawl (cào/ phân tích) dữ liệu trên trang web để khám phá nội dung
- Index nội dung đó để đáp ứng yêu cầu cho các tìm kiếm của người dùng
Để crawl được dữ liệu của trang web thì các công cụ tìm kiếm sẽ đi theo các liên kết từ trang này đến trang khác. Cuối cùng, nó thu thập được dữ liệu thông qua hàng tỷ trang web khác nhau.
Quá trình crawl dữ liệu này còn được biết đến với tên khác là “spidering”.
Sau khi đến một trang web, trước khi spidering thì các con bot của công cụ tìm kiếm sẽ tìm các file robots.txt wordpress. Nếu nó tìm thấy được 1 tệp robots.txt thì nó sẽ đọc tệp đó đầu tiên trước khi tiến hành các bước tiếp theo.
File robots.txt chứa các thông tin về cách các công cụ tìm kiếm nên thu thập dữ liệu của website. Tại đây các con bot này sẽ được hướng dẫn thêm nhiều thông tin cụ thể cho quá trình này.
Nếu tệp robots.txt không chứa bất kì chỉ thị nào cho các user-agent hoặc nếu bạn không tạo file robots.txt cho website thì các con bots sẽ tiến hành thu thập các thông tin khác trên web.
Một số lưu ý cho robots.txt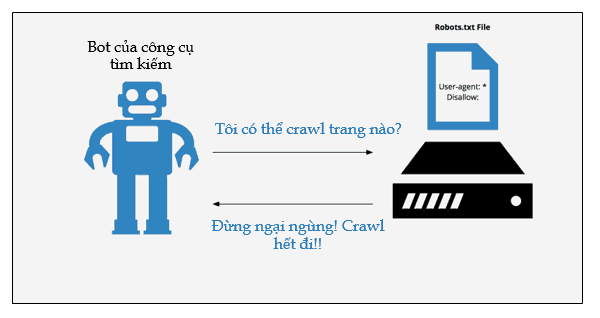
- Để được các con bot tìm thấy thì các tệp file robots.txt phải được đặt trong các thư mục cấp cao nhất của trang web.
- txt có thể phân biệt chữ hoa và chữ thường. Vì thế tệp phải được đặt tên là robots.txt. (không phải Robots.txt hay robots.TXT, …)
- Không nên đặt /wp-content/themes/ hay /wp-content/plugins/ vào mục Disallow. Điều đó sẽ cản trở các công cụ tìm kiếm nhìn nhận chính xác về giao diện blog hay website của bạn.
- Một số user-agent có thể chọn cách bỏ qua các file robots.txt chuẩn của bạn. Điều này khá phổ biến với các user-agent bất chính như:
- Malware robots (bot của các đoạn mã độc hại)
- Các trình scraping (quá trình tự thu thập thông tin) địa chỉ email
- Các tệp robots.txt thường có sẵn và được công khai trên web. Bạn chỉ cần thêm /robots.txt vào cuối bất kì root domain để xem các chỉ thị của trang web đó.
Điều này có nghĩa là bất kì ai cũng có thể thấy các trang bạn muốn hoặc không muốn crawl. Vì vậy đừng sử dụng các tệp này để ẩn thông tin cá nhân của người dùng. - Mỗi sub domain trên một một root domain sẽ sử dụng các file txt wordpress riêng biệt. Điều này có nghĩa là cả blog.example.com và example.com nên có các tệp robots.txt riêng. (blog.example.com/robots.txt và example.com/robots.txt). Tóm lại, đây được xem là cách tốt nhất để chỉ ra vị trí của bất kì sitemaps nào được liên kết với domain ở cuối tệp robots.txt.
Robot.txt đi đâu trên một trang web?
Bất kể khi nào đến với một trang web, các công cụ tìm kiếm hay các web crawler (ví dụ như Facebook’s crawler, Facebot) sẽ ngay lập tức tìm kiếm tệp robot.txt.
Tuy nhiên, nó chỉ tìm ở một nơi cụ thể. Đó chính là thư mục chính (root domain hay trang chủ).
Ví dụ nếu user-agent truy cập www.example.com/robots.txt và không tìm thấy tệp robots.txt ở đó, nó sẽ cho rằng trang web này không hề tạo file robots.txt cho wordpress.
Ngay lúc này nó sẽ tiến hành thu thập dữ liệu của toàn bộ trang web.
Một số trường hợp là các tệp robots.txt này có tồn tại nhưng không được tìm thấy bởi các web crawler. Mặc nhiên, nó sẽ được xử lí tương tự như trang web không được tạo file robots.txt cho wordpress.
Để đảm bảo các trình thu thập dữ liệu có thể tìm thấy được tệp robots.txt của bạn. Hãy luôn để nó trong các thư mục chính hoặc root domain.
Tại sao bạn cần tạo file robots.txt cho wordpress?
Việc tạo file robots.txt cho wordpress giúp bạn kiểm soát việc truy cập của các con bots đến các khu vực nhất định trên trang web. Và điều này có thể vô cùng nguy hiểm nếu như bạn vô tình sai một vài thao tác khiến Googlebot không thể index website của bạn.
Tuy nhiên, việc tạo file robots.txt cho wordpress vẫn thật sự hữu ích bởi nhiều lí do:
- Ngăn chặn nội dung trùng lặp xuất hiện trong website (lưu ý rằng các robot meta thường là lựa chọn tốt hơn cho việc này)
- Giữ một số phần của trang web ở chế độ riêng tư
- Giữ các trang kết quả tìm kiếm nội bộ không hiển thị trên SERP
- Chỉ định vị trí của sitemap
- Ngăn các công cụ tìm kiếm index một số tệp nhất định trên trang web của bạn (hình ảnh, PDF, …)
- Dùng lệnh crawl delay để cài đặt thời gian. Điều này sẽ ngăn việc máy chủ của bạn bị quá tải khi các trình thu thập dữ liệu tải nhiều nội dung cùng một lúc.
Nếu bạn không muốn ngăn các web crawler tiến hành thu thập dữ liệu từ website thì bạn hoàn toàn không cần tạo file robots.txt cho wordpress.
Làm thế nào để kiểm tra website có tệp robots.txt không?
Nếu bạn đang băn khoăn không biết website của mình có tệp robots.txt không. Hãy nhập root domain của bạn, sau đó thêm /robots.txt vào cuối URL. Nếu không có trang .txt xuất hiện, thì chắc chắn website bạn hiện không tạo robots.txt cho wordpress rồi. Rất đơn giản!
Tương tự, bạn có thể kiểm tra website beeseo.vn có tạo file robots.txt hay không bằng cách như trên:
Nhập root domain (beeseo.vn) > chèn /robots.txt vào cuối (kết quả là beeseo.vn/robots.txt) > Nhấn Enter
Và đợi kết quả là biết ngay thôi!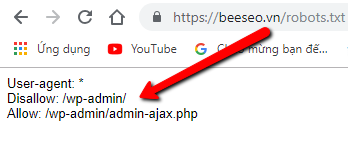
Cách tạo tệp robots.txt cho wordpress
Nếu sau khi kiểm tra, bạn nhận thấy website của mình không có tệp robots.txt hay đơn giản là bạn đang muốn thay đổi tệp robots.txt của mình. Hãy tham khảo 3 cách tạo file robots.txt cho wordpress dưới đây:
1. Sử dụng Yoast SEO
Bạn có thể chỉnh sửa hoặc tạo tệp robots.txt cho wordpress trên chính WordPress Dashboard với vài bước đơn giản.
Đăng nhập vào website của bạn. Khi đăng nhập vào, bạn sẽ thấy giao diện của trang Dashboard.
Nhìn phía bên trái màn hình, click vào SEO » Tools » File editor.
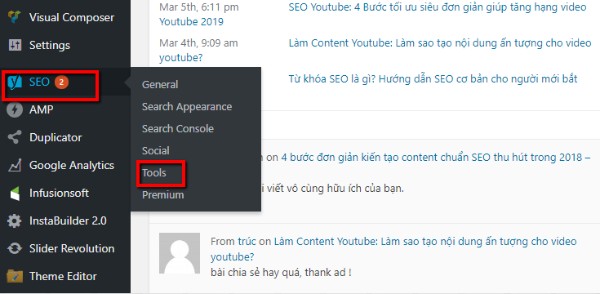
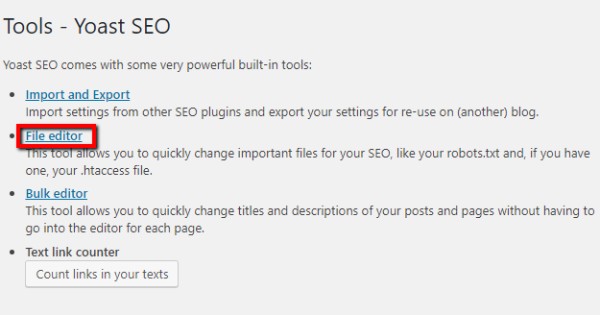
Tính năng File editor sẽ không xuất hiện nếu wordpress của bạn vẫn chưa được kích hoạt tính chỉnh sửa file. Do vậy hãy kích hoạt chúng thông qua FTP (File Transfer Protocol – Giao thức truyền tập tin).
Lúc này bạn sẽ thấy mục .htaccess file và một nút Create robots.txt file – đây là nơi giúp bạn tạo file robots.txt
2. Qua bộ plugin All in One SEO
Hoặc bạn có thể sử dụng bộ plugin All in One SEO để tạo file robots.txt nhanh chóng. Đây cũng là một plugin tiện ích cho wordpress – Đơn giản, dễ sử dụng.
Để tạo file robots.txt, bạn phải đến giao diện chính của plugin All in One SEO Pack.
Chọn All in One SEO » Features Manager » Nhấp Active cho mục robots.txt
Lúc này, trên giao diện sẽ xuất hiện nhiều tính năng thú vị:
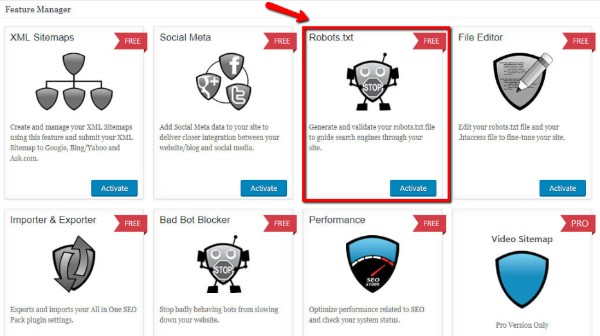
Và khi đó, mục robots.txt sẽ xuất hiện như một tab mới trong thư mục lớn All in One SEO. Bạn có thể tạo lập cũng như điều chỉnh file robots.txt tại đây. Tuy nhiên, bộ plugin này có một chút khác biệt so với Yoast SEO tôi vừa đề cập ở trên.
All in One SEO làm mờ đi thông tin của file robots.txt thay vì bạn được chỉnh sửa file như công cụ Yoast SEO. Điều này có thể khiến bạn hơi bị động một chút khi chỉnh sửa file robots.txt.
Tuy nhiên, tích cực mà nói, yếu tố này sẽ giúp bạn hạn chế thiệt hại cho website của mình. Đặc biệt một số malware bots sẽ gây hại cho website mà bạn không ngờ tới.
3. Tạo rồi upload file robots.txt WordPress qua FTP
Nếu bạn không muốn sử dụng plugin để tạo file robot.txt thì tôi có 1 cách này cho bạn – Tự tạo file robots.txt thủ công cho wordpress của mình.
Bạn chỉ mất vài phút để tạo file robots.txt này bằng tay. Sử dụng Notepad hoặc Textedit để tạo mẫu file robots.txt theo rule tôi đã giới thiệu ở đầu viết.
Sau đó upload file này qua FTP không cần sử dụng plugin. Quá trình này rất đơn giản không tốn bạn quá nhiều thời gian đâu.
Một số lưu ý khi sử dụng file robots.txt
Hãy đảm bảo rằng bạn không chặn bất kì nội dung hoặc phần nào trên trang web mà bạn muốn Google index.
Các liên kết trên trang bị chặn bởi việc tạo file robot txt sẽ không được các bots theo dõi. Trừ khi các links này có liên kết với các trang khác (các trang không bị chặn bởi robots.txt, meta robots,…). Nếu không các tài nguyên được liên kết có thể sẽ không được thu thập và index.
Link juice sẽ không được truyền từ các trang bị chặn đến các trang đích. Vì thế nếu muốn dòng sức mạnh link juice truyền qua các trang này thì bạn hãy sử dụng một phương pháp khác thay vì tạo file robots.txt cho wordpress.
Không sử dụng file robot.txt chuẩn để ngăn dữ liệu nhạy cảm (như thông tin người dùng riêng tư) xuất hiện trong kết quả SERP.
Bởi vì trang web chứa thông tin cá nhân này có thể liên kết với nhiều trang web khác. Do đó các con bots sẽ bỏ quá các chỉ thị của tệp robots.txt trên root domain hay trang chủ của bạn, nên trang web này vẫn có thể được index.
Nếu bạn muốn chặn trang web này khỏi các kết quả tìm kiếm, hãy sử dụng một phương pháp khác thay vì tạo file robots.txt cho wordpress như dùng mật khẩu bảo vệ hay noindex meta directive.
Một số công cụ tìm kiếm có rất nhiều user-agent. Chẳng hạn, Google sử dụng Googlebot cho các tìm kiếm miễn phí và Googlebot-Image cho tìm kiếm hình ảnh.
Hầu hết các user-agent từ cùng một công cụ tìm kiếm đều tuân theo một quy tắc. Do đó bạn không cần chỉ định các lệnh cho từng user-agent. Tuy nhiên việc làm này vẫn có thể giúp bạn điều chỉnh được cách index nội dung trang web.
Các công cụ tìm kiếm sẽ lưu trữ nội dung file robots.txt wordpress. Tuy nhiên nó vẫn thường cập nhật nội dung trong bộ nhớ cache ít nhất một lần một ngày. Nếu bạn thay đổi tệp và muốn cập nhật tệp của mình nhanh hơn thì có thể gửi robots.txt url cho Google.
Robots.txt, meta robot và x-robot
Robots.txt, meta robot và x-robot, sự khác biệt giữa các loại robot này là gì?
Đầu tiên, robots.txt là một tệp văn bản trong khi meta robot và x-robot là các meta directives. Ngoài ra, chức năng của 3 loại robot này cũng hoàn toàn khác nhau.
Việc tạo file robots txt ra lệnh cho việc index toàn bộ trang web hoặc thư mục.Trong khi đó thì meta robot và x-robot có thể ra lệnh cho việc index ở cấp độ trang riêng lẻ.
Kết luận
Bây giờ đến lượt bạn rồi đấy! Kiểm tra xem website của mình đã có file robots.txt chưa. Tạo lập và chỉnh sửa file robots.txt theo ý của bạn nhằm hỗ trợ các con bot của công cụ tìm kiếm thu thập dữ liệu và index trang web của bạn nhanh chóng.
Nếu gặp bất kỳ vấn đề nào trong quá trình tạo file cũng như chỉnh sửa robots.txt, comment bên dưới bài viết nhé! Beeseo sẽ trả lời sớm cho bạn.
Chúc bạn thành công.
Beeseo
Nguồn: Vincent Do












{kind=link}